| индекс | ||||||
|
УДК 004.82 ВВЕДЕНИЕ В МОРФОЛОГИЧЕСКИЕ МЕТОДЫ ИССЛЕДОВАНИЯ
|
|||||||||||||||||||||||||||||
| Форма столешницы | Форма сечения ножек | Число ящиков | |
|---|---|---|---|
| Обеденный стол | прямоугольная, круглая, овальная | прямоугольная, круглая | 0 |
| Письменный стол | прямоугольная | прямоугольная, круглая | 2,3,4 |
| Наличие замка | присутствует, отсутствует |
|---|
| Форма столешницы | прямоугольная, круглая, овальная |
|---|---|
| Форма сечения ножек | прямоугольная, круглая |
Сравним использование морфологических деревьев и таблиц. Морфологические деревья наглядно отражают морфологическое множество. Они могут быть легко декомпозированы на поддеревья. Поэтому применение морфологических И/ИЛИ-деревьев представляется целесообразным. Морфологические таблицы для сколь либо сложных систем получаются многоуровневыми. Более того, отсутствует какой либо стандарт на структуру таких таблиц. Поэтому использование морфологических таблиц представляется целесообразным лишь для достаточно простых морфологических множеств, где можно обойтись одноуровневыми таблицами.
Используя модель М1, представленную тем или иным образом, мы можем однозначно идентифицировать объект, назвав все значения его классификационных признаков. Но такая модель не дает нам непосредственно информацию о структуре идентифицированного объекта. Поэтому чтобы восстановить по М1 структуру объекта, нам необходим некий словарь, который бы связывал значения классификационных признаков с некими примитивами, из которых строятся объекты предметной области. Назовем такой словарь словарем морфологического множества.
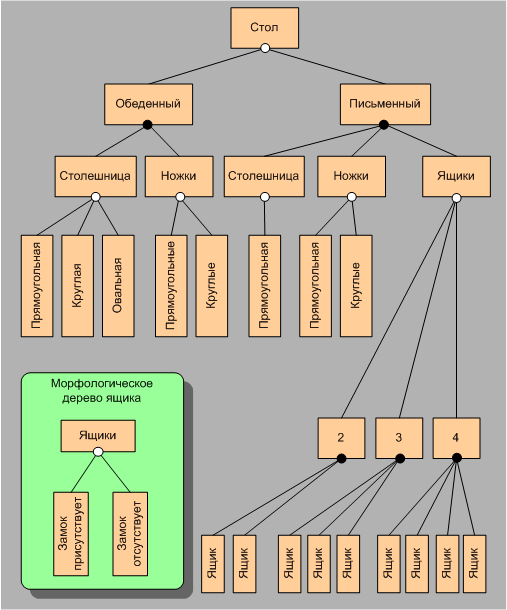
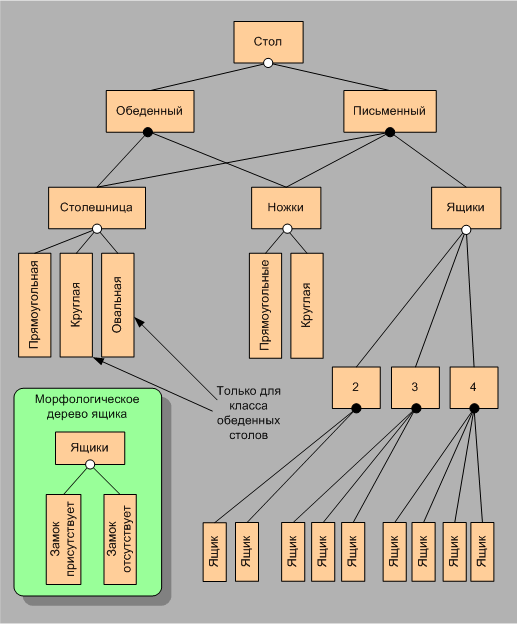
Так для нашего случая со столом, нам надо определить, как выглядят столешницы, ножки стола, ящики и замки, дав их чертежи или спецификации. Тогда двигаясь вдоль морфологического И-дерева с вырожденными ИЛИ-вершинами, мы будем выбирать из этого словаря соответствующие спецификации и собирать из них общую спецификацию объекта. Если объединить модель М1 со словарем и задать правила, как, используя этот словарь по идентификатору объекта построить его спецификацию, то получим модель на новом, более высоком, качественном уровне.
Так как эта модель описывает морфологическое множество целиком, на уровне спецификаций, то естественно назвать ее моделью морфологического множества уровня спецификации или просто моделью морфологического множества. В отличие от модели М1, такая модель позволяет не только идентифицировать объект, но и получить его спецификацию, и тем самым является гораздо более содержательной. Кроме того, она включает в себя модель М1 в качестве модели более низкого уровня иерархии. Назовем эту модель моделью М2.
Пример 2. Пусть мы хотим создать модель морфологического множества столов используя результаты, полученные в примере 1.
Рассмотрим словарь морфологического множества для нашего случая со столами. В такой словарь должны входить спецификации для столешниц разных форм: прямоугольных, круглых и овальных; ножек двух видов сечений: прямоугольных и круглых; а так же ящиков, как с замками, так и без замков. Тогда, используя этот словарь мы можем по элементу морфологического множества, представленному, например, морфологическим И-деревом с вырожденными ИЛИ-вершинами получить спецификацию стола, соответствующую выбранным значениям классификационных признаков. Совокупность модели М1, словаря морфологического множества и правил получения общей спецификации по спецификациям элементов словаря будет представлять собой модель морфологического множества или модель М2.
Итак, М2 позволяет получить спецификацию структуры любого объекта принадлежащего рассматриваемому классу. Но такая модель не позволяет провести анализ этого объекта, не дает возможность получить какие-либо характеристики объекта отличные от структурных. Из нее непосредственно не вытекают системы уравнений, описывающие объект. Если помимо возможности восстановления структуры объекта по значениям классификационных признаков возможно составить систему уравнений, описывающую объект, и решить ее, тоесть провести всесторонний анализ объекта, не только структурный, но и функциональный, то такая модель будет уже будет не моделью морфологического множества, а моделью класса устройств или универсальной моделью или метамоделью. Эта модель будет моделью третьего уровня (уровня симуляции), или моделью М3. Она включает в себя модели М1 и М2, точно так же как М2 включает в себя М1.
Такак как модель М2 позволяет по значениям классификационных признаков получить спецификацию объекта, используя эту спецификацию, представленную на входном языке некоего пакета моделирования, возможно передать ее в данный пакет и провести анализ идентифицированного объекта в том объеме, который обеспечивается этим пакетом. Ввиду того, что сейчас пакеты компьютерного моделирования от различных производителей получили достаточно широкое распространение, в случае наличия подходящего для моделирования исследуемого класса устройств (объектов) можно ограничится моделированием морфологического множества, а получаемые спецификации устройств передавать в этот пакет, где и проводить весь необходимый анализ. Таким образом, мы разделяем моделирование структур и функциональное моделирование. Это полностью соответствует современной тенденции модульного программирования, когда вместо того, чтобы писать программу целиком, ее собирают из готовых модулей, а пишут лишь отсутствующие.
Это сокращает объем работ и, кроме того, система получается более надежной, так как в ней используются модули, которые должны работать во многих различных системах и которые поэтому пишутся, отлаживаются и тестируются наиболее тщательно. Более того, мы разделяем различные виды знаний: моделирования структур и традиционного математического моделирования, что так же положительно с методологической точки зрения.
В предыдущих пунктах было дано определение морфологического анализа, моделей морфологического множества и класса устройств, а также предложена методология получения таких моделей. В данном пункте будут рассмотрены вопросы поиска структурных решений, проектируемых объектов, осуществляемые методами морфологического синтеза на вышеупомянутых моделях.
Обычно помимо нахождения структуры необходимо найти параметры элементов, составляющих эту структуру. Более того, часто мы даже не можем провести оценку структуры, не проведя параметрический синтез, что, в частности, характерно для синтеза радиотехнических устройств. Поэтому, внутри каждого шага морфологического синтеза осуществляется еще и параметрический.
Так как методы параметрического синтеза заслуживают отдельного рассмотрения, они здесь упоминаться не будет.
Классификация методов морфологического синтеза предложена в работе [4]. Здесь же будет приведена классификация несколько отличная от предложенной в упомянутых работах. Предлагаемая классификация, ориентированна на программную реализацию морфологических методов синтеза и, на взгляд автора, лучше отражает специфику данной задачи.
Итак, согласно предлагаемой классификации методы морфологического синтеза делятся на методы генерации структур и трансформации структур.
В случае генерации структуры процесс синтеза начинается как бы с нуля: у нас отсутствует первое приближение или прототип. Для методов трансформации структуры, напротив, необходима структура, которую они должны последовательно улучшать.
Далее, методы генерации структур делятся на методы зондирования морфологического множества и методы морфологического конструирования. В первом случае выбирается вся схема целиком, по крайней мере на уровне подсистем. Во втором – объект создается постепенно. Методы морфологического зондирования как и морфологического конструирования, могут быть одноуровневыми, когда за раз выбирается структура всей системы, и многоуровневыми, когда последовательно проводится синтез на разных уровнях иерархии, сначала системы, затем подсистем.
Методы трансформации структуры делятся на методы случайного блуждания и методы целенаправленного совершенствования прототипа. Следует отметить, что методы генерации структуры ориентированы на поиск глобального экстремума, трансформации структуры – локального. Здесь полная аналогия с математическим программированием.
Для реализации этих методов необходимы два класса эвристик: технические эвристики и эвристики трансформации. Технические эвристики обеспечивают простое изменение структуры объекта, например, увеличение или уменьшения порядка лестничной цепи, перевод цепи в дуальную и т. д. Эвристики трансформации в свою очередь являются эвристиками более высокого уровня абстракции, они используют технически эвристики и служат для непосредственного направления ходя структурной оптимизации. Они, например, могут отвечать на вопрос что необходимо сделать для уменьшения неравномерности АЧХ, снижения суммарной индуктивности и т. п.
В случае зондирования морфологического множества выбирается элемент морфологического множества для одноуровневых систем или его окрестность - для случая синтеза иерархических систем. Выбор такого элемента может происходить как случайным образом, так и при помощи использования правил полученных на основе анализа экспертных знаний. Зондирование может быть случайным или детерминированным. Частным случаем последнего может быть полный или неполный перебор, который возможен лишь в случае небольшой мощности морфологического множества.
Алгоритмы зондирования могут быть неадаптивными и адаптивными. Неадаптивные алгоритмы осуществляют генерацию каждой новой структуры (зондируют морфологическое множество) независимо от уже сгенерированных структур. В случае адаптивных алгоритмов, генерация последующих структур осуществляется с учетом предыдущих. Адаптивный алгоритм сужает область поиска и стремиться (или находит) глобальный экстремум (самую лучшую структуру).
В отличие от методов зондирования, когда структура выбирается целиком, алгоритмы морфологического конструирования создают (конструируют) систему последовательно, подсистема за подсистемой. Основными методами морфологического конструирования являются: независимая оценка подсистем, древовидное и лабиринтное конструирование.
Простейшим методом морфологического конструирования является независимая оценка подсистем. В этом методе выбираются наилучшие технические решения подсистем, не учитывая технические решения других подсистем. Здесь предполагается, что система, будучи составленной из оптимальных подсистем, сама является оптимальной, что вообще говоря, с позиций системного подхода является неверным.
Впрочем, здесь возникают и другие трудности. Во-первых, не всегда удается заранее определить состав подсистем. Так, например, для усилителя необходимо знать, как минимум, число каскадов. Этот метод для синтеза усилителей СВЧ может быть применен лишь для синтеза усилительных четырехполюсников. Для синтеза же цепей связи (согласующих цепей) он представляется непригодным. В самом деле, выбрать структуры цепи связи, не учитывая характеристики усилительных четырехполюсников, не представляется возможным.
Более совершенным методом является метод древовидного конструирования. Сначала проводится ранжирования подсистем по значимости выполняемой ими функций. Далее выбирается наиболее оптимальное техническое решение самой значимой подсистемы, после чего выбирается следующая подсистема, но уже с учетом первой. Потом выбирается третья с учетом уже существующих двух предыдущих и т. д. пока не будет получена структура всей системы.
По сравнению с методом независимой оценки подсистем древовидное конструирование является более гибким и дает возможность получить более оптимальное техническое решение. Этот метод может быть применен для синтеза транзисторных усилителей СВЧ-диапазона.
В самом деле, сначала мы можем синтезировать усилительные четырехполюсники, начиная с первого каскада для малошумящих усилителей (именно первый каскад будет определять качество усилителя) и с последнего, для случая усилителей мощности. Причем синтезировать усилительные четырехполюсники мы будем с учетом уже существующих. Далее синтезируются цепи связи (согласующие цепи).
Следует заметить, что УЧ можно выбирать и независимо, используя метод независимой оценки. Впрочем, возможна и другая последовательность синтеза функциональных элементов: сначала первый усилительный четырехполюсник; затем входная цепь связи; второй усилительный четырехполюсник; межкаскадная цепь связи и т. д. Такая последовательность не требует предварительного задания числа каскадов, а останов алгоритма произойдет после удовлетворения всем условиям технического задания.
Достоинством данного метода является то, что он дает возможность получить техническое решение проектируемого устройства за один проход. Но в этом и его недостаток. Так в случае двух подсистем мы действительно получим оптимальное решение. В самом деле, сначала выбирается наиболее значимая подсистема и, далее, с ее учетом, находится вторая.
Но уже в случае трех подсистем, древовидное конструирование не дает гарантии нахождения глобально оптимальной структуры. Мы выбираем третью подсистему с учетом уже существующих двух других. Поэтому если рассматривать уже созданную часть системы как данность, то система будет оптимальной. Но не факт, что отсутствует сочетание, не являющееся оптимальным для случая двух самых значимых подсистем, но которое будет лучшим для случая системы в целом. Но несмотря на это, древовидное конструирование может быть использовано для получения первого приближения, с последующим улучшением его методами трансформации структуры.
Следующим методом является лабиринтное конструирование. Здесь, как и в методе древовидного конструирования сначала выбирается самая значимая подсистема. Но помимо лучшей здесь выбирается еще и несколько запасных. Далее выбирается следующая лучшая подсистема, так же с несколькими запасными вариантами. Если процесс конструирования зашел в тупик, тоесть выбранная часть системы не удовлетворяет ограничениям, то происходит возврат и выбирается запасной вариант подсистемы. Причем возврат может осуществляться как на один, так и на большее число шагов, вплоть до первой выбранной подсистемы. Такой процесс продолжается до тех пор, пока не будет получена структура всей системы.
Следует заметить, что и лабиринтное конструирование не дает гарантии нахождения глобального оптимума и происходит это по тем же причинам, что и в случае древовидного конструирования. Для увеличения вероятности нахождения им глобального оптимума можно ввести элемент случайности, введя вероятность выбора варианта подсистемы, основываясь на том, что лучшие варианты должны иметь более высокие вероятности выбора по сравнению с другими. Иными словами, функция вероятности выбора варианта должна быть монотонной функцией от оптимальности этого варианта. Тогда запустив алгоритм лабиринтного конструирования несколько раз, можно выбрать наилучшее из полученных технических решений.
При синтезе ТУ СВЧ весьма перспективным представляется модифицированный метод лабиринтного конструирования [13]. В отличие от классического варианта в модифицированном методе на каждом шаге проводится параметрическая оптимизация полученной структуры, которая может быть дополнена структурной оптимизацией при помощи метода совершенствования прототипа.
В качестве примера рассмотрим стратегию синтеза малошумящего транзисторного усилителя на основе каскадной базовой усилительной структуры (БУС).
Сначала синтезируется первый . Он (как и другие усилительные четырехполюсники) может представлять собой как транзистор, содержащий различные корректирующие цепи, так и сколь угодно сложную БУС. Затем синтезируется входная цепь связи и проводится оптимизация полученной структуры. Далее синтезируется второй усилительный четырехполюсник. После этого проводится синтез цепей связи между первым и вторым усилительными четырехполюсниками и проводится оптимизация полученной структуры.
Этот процесс продолжается до получения окончательной усилительной структуры, которая будет удовлетворять техническому заданию.
В процессе синтеза может оказаться, что полученная на ранних этапах структура не позволит удовлетворить условиям технического задания при дальнейшем наращивании или будет заведомо неоптимальной. В этом случае необходимо вернуться на несколько шагов назад и попытаться заново провести синтез.
В заключении следует отметить, что древовидное конструирование можно считать частным случаем лабиринтного, когда отсутствует механизм возврата, а метод независимой оценки подсистем – частным случаем древовидного.
Метод совершенствования прототипа относится к классу методов трансформации структур. Сущность данного метода следующая. Сначала мы выбираем предварительную структуру проектируемого устройства или структуру прототипа, а затем начинаем ее улучшение или совершенствование. Отсюда и название – совершенствование прототипа. Такое совершенствование осуществляется по следующему алгоритму.
Смысл алгоритма очевиден. Мы выбираем структуру прототипа проектируемого устройства, тем самым, задаваясь первым приближением. Затем начинаем его последовательное улучшение, приближаясь к оптимальному решению. Но насколько такой алгоритм позволит отыскать лучшее решение или, иными словами, достигнуть глобального оптимума?
Первое ограничение: мы никогда не выйдем за пределы морфологического множества. Этот алгоритм, как и все алгоритмы морфологического синтеза, осуществляет поиск лишь в границах морфологического множества, полученного в результате морфологического анализа и реализованного в модели класса устройств. Но является ли такое ограничение слишком сильным? Ведь и разработчик обычно ищет рациональное техническое решение, оставаясь в рамках структур объектов известных классов устройств. Современное состояние теории интеллектуальных систем (систем искусственного интеллекта) не в состоянии создать алгоритм который позволил бы синтезировать принципиально новые структуры, не сводимые к известным базовым структурам и элементам. Но вполне возможно создать алгоритм, который будет синтезировать структуры, комбинируя уже известные структуры и элементы и получать объекты с требуемыми свойствами. За счет того, что современная вычислительная техника обладает большой вычислительной мощью, которая к тому же продолжает стремительно возрастать, возможно создание программ, которые способны решать задачи синтеза не хуже большинства разработчиков. И даже в случае создания принципиально новых объектов, программы поддержки принятия проектных решений все равно могут оказаться очень полезными, так как, смоделировав класс только что изобретенных устройств, можно будет провести его всесторонний анализ, выявить сильные и слабые стороны, и в дальнейшем включить в стандартные библиотеки автоматизированного синтеза. А, следовательно, цель автоматизации структурно-параметрического синтеза – не подменить, а дополнить человека, оставить человеку решать лишь творческие задачи, переложив всю рутину на плечи компьютеров.
Рассмотренный выше алгоритм не является адаптивным. Он случайным образом модифицирует структуру объекта и как бы блуждает по морфологическому множеству. Отсюда и название этого алгоритма – алгоритм случайного блуждания. Здесь можно провести аналогию с алгоритмом покоординатного спуска в теории НЛП. Но можно сделать так, что модификация структуры будет направляться эвристиками, полученными в результате анализа экспертных знаний в предметной области. Например, известно, что уменьшить неравномерность АЧХ СВЧ усилителя, можно путем добавления цепей обратных связей, амплитудных корректоров или увеличением порядка согласующих цепей. Очевидно, что такой алгоритм будет обеспечивать гораздо более быструю сходимость по сравнению со случаем случайного блуждания. Но здесь может подстерегать другая опасность: уменьшается пространство поиска, или точнее сужаются габариты коридора, в котором происходит трансформация структуры.
Алгоритм целенаправленного совершенствования прототипа по существу является нечетким регулятором, изучаемым в теории систем основанных на знаниях, который приспособлен для нужд морфологического синтеза. Это дает возможность воспользоваться хорошо разработанной теорией и практикой реализации нечетких регуляторов, разработанными в соответствующем разделе науки об интеллектуальных системах.
Методы морфологического синтеза служат для нахождения структур проектируемых устройств. Они делятся на методы генерации и трансформации структур. Первые ориентированы на поиск глобального экстремума, вторые – локального. Здесь полная аналогия с математическим программированием.
Генерация структуры может быть адаптивной, когда последующие структуры генерируются с учетом уже сгенерированных структур.
В случае иерархических систем сначала синтезируется система на самом высоком уровне абстракции. Далее синтезируются подсистемы.
Следует заметить, что все изложенные здесь алгоритмы являются скорее шаблонами, по которым строятся конкретные алгоритмы, нацеленные на решение реальных задач. Здесь уместно провести аналогию с известным алгоритмом комивояжора.
Модель М3 позволяет провести всесторонний анализ любого устройства принадлежащего рассматриваемому классу, заданное значениями классификационных признаков. Поэтому эта модель является моделью уровня анализа. На такой модели возможно проводить структурно-параметрический синтез при помощи модуля, реализующего алгоритмы такого синтеза.
Но в настоящий момент, отсутствуют универсальные алгоритмы, позволяющие проводить структурно-параметрический синтез за приемлемое время. Поэтому используются различные эвристики, взятые из конкретных предметных областей. Если мы для данного класса объектов помимо знаний их моделирования приведем формализованные знания задания на синтез и эвристики, применяемые при проектировании, то получим модель предметной области или модель М4 [8-10].
Модель М4 является моделью М3 дополненной знаниями, необходимыми для синтеза объектов данного класса. Иными словами, модель предметной области представляет собой модель класса устройств дополненную алгоритмами синтеза этих устройств по техническому заданию. Поэтому модель М4 является моделью уровня синтеза. А так как она интегрирует в себя все типы знаний предметной области, то такую модель можно назвать моделью уровня интеграции.
Итак, мы ввели 4 класса моделей: М1 – М4. Модель М1 соответствует уровню идентификации; М2 – уровню спецификации; М3 – уровню реализации; М4 – уровню интеграции. Эти модели представляют собой систему. Особенностью такой системы является то, что модели верхних уровней иерархии включают в себя модели нижних уровней (рис. 3). С другой стороны они представляют разные виды знаний, для формализации которых требуются различные способы представления. Информацию о таком представлении можно заключить в отдельные модули, что ведет к разделению знаний по слоям, что является положительным с точки зрения современных методологий инженерии знаний.
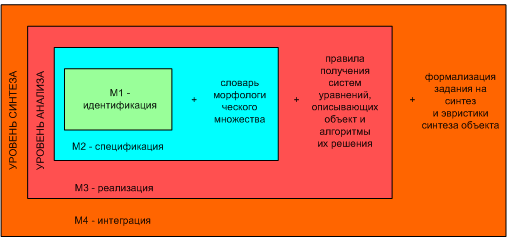
Рис. 3. Структура четырехуровневой интегративной модели области знаний
Морфологические методы являются мощным аппаратом исследования в различных областях знаний. Сущность морфологических методов заключается в следующем: сначала в результате морфологического анализа мы определяем пространство поиска, называемое морфологическим множеством, которое обязательно должно включать в себя искомое решение (структуру объекта), а затем сужаем это пространство, осуществляя поиск этого решения, которое является элементом морфологического множества.
Но морфологические методы оперируют лишь понятиями структур объектов, следовательно, они моделируют только часть знаний предметной области, относящуюся к морфологии. Поэтому для моделирования знаний предметной области морфологические методы должны быть дополнены методами математического моделирования рассматриваемых объектов, а также методами инженерии знаний. Для моделирования знаний предметной области используются модели четырех уровней М1 – М4, соответствующих уровням идентификации, спецификации, симуляции и интеграции.
Модель М1, или модель морфологического множества уровня идентификации – это модель, которая однозначно идентифицирует устройство, не давая его спецификации. Она соответствует морфологическому И/ИЛИ-дереву для случая морфологического множества и морфологическому И-дереву с вырожденными ИЛИ-вершинами для элемента морфологического множества (конкретно взятого устройства). Ключевое слово – идентификация. А следовательно, это модель уровня идентификации.
Модель М2, или модель морфологического множества это – модель, которая позволяет получить спецификацию, однозначно описывающую любое устройство, принадлежащее рассматриваемому классу. Здесь ключевое слово – спецификация, поэтому и модель будет уровня спецификации.
Модель М3, модель класса устройств или универсальная модель – модель всего класса устройств, позволяющая анализировать любое конкретно взятое устройство, принадлежащее классу рассматриваемых устройств.
Модель М4 – модель знаний предметной области. Интегрирует знания рассматриваемой предметной области. Она является моделью класса устройств М3, дополненную экспертными знаниями из предметной области, позволяющими проводить синтез. Если модели М1 – М3 являются моделями уровня анализа, то М4 является моделью уровня синтеза. Ключевое слово интеграция. Следовательно, это модель уровня интеграции.
Применение моделей четырех указанных типов позволяет смоделировать предметную область, представить знания более формализовано, более строго, чем это обычно делается. Кроме того, такие модели допускает компьютерную реализацию на всех иерархических уровнях, позволяя интегрировать широко используемые пакеты моделирования. Кроме того, в них осуществляется разделение различных видов знаний: морфологических (структурных) знаний, знаний о математическом моделировании и знаний, представленных эвристиками, применяемыми разработчиками при проектировании устройств.
| Кто Вы? |
|
|
| Результаты голосования |
| ©Structuralist
2005-2006 structuralist@narod.ru |
|
|